Address
128 City Road, London EC1V 2NX
Work Hours
Monday to Friday: 8AM - 4PM
Weekend: 10AM - 2PM

Address
128 City Road, London EC1V 2NX
Work Hours
Monday to Friday: 8AM - 4PM
Weekend: 10AM - 2PM


One of the key components of SEO is website crawlability, which is the ability of a search engine to crawl, or index, your website’s content. Crawlability is the process of a search engine going through your website’s content and identifying new content, as well as updating existing content, to be included in the search engine’s index.
Without proper crawlability, your website’s content may not show up in search results, which can have a devastating effect on your website’s visibility. In this blog post, we’ll discuss what website crawlability is, why it’s important, and how you can make your content crawlable. We’ll also provide tips and best practices to help you maximise your website’s SEO potential.
Crawlability refers to the ability of search engine crawlers to access and analyze the content on a website. It is a crucial aspect of search engine optimization (SEO) as it directly impacts a website’s visibility in search results.
To ensure crawlability, it is important to address certain factors that can hinder the crawling process. Broken links, for example, can lead to dead ends for search engine crawlers, preventing them from indexing the desired content. Similarly, server errors such as 5xx error codes can hinder the crawling process and result in pages being inaccessible to search engine bots.
Crawlability is essential for effective SEO. By addressing issues such as broken links, server errors, looped redirects, robots.txt blocking issues, and ensuring a solid internal link structure, websites can improve their crawlability, leading to better search engine visibility and organic traffic.
Additionally, ensure that you have a fast and reliable hosting platform, and that all the internal links on your website are working properly. By taking these steps, you can make sure that your content is easily crawlable and discoverable by search engines.
Ensuring that your website’s content is crawlable is crucial for search engine optimization (SEO) purposes. The crawlability of a website refers to how easily search engine bots can access and navigate through its pages. By addressing common crawlability issues, you can improve the chances of your website’s content being indexed and ranked by search engines. In this article, we will discuss several common crawlability issues and how to overcome them to ensure that your website’s content is easily discoverable by search engines.
By addressing these common crawlability issues, you can improve the visibility of your website’s content and enhance its chances of ranking higher in search engine results pages.
Non-HTML links, such as those contained within frames, JavaScript, or Flash, pose a challenge for search engine crawlers. These types of links may not be properly indexed and crawled, resulting in potential crawlability issues.
To address this issue, it’s crucial to ensure that important links on your website are formatted in HTML. HTML links are easily understood by search engine bots, making it more likely for them to be indexed and properly crawled.
One effective way to check if your non-HTML links are appearing in the search engine’s index is to compare the text-only version of your page with the full page. Google offers a text-only version of web pages within their cached search results. By viewing this version, you can determine if the non-HTML links are visible in the cached text. If the links are missing, it’s a sign that search engine crawlers may not be able to access them.
By addressing non-HTML links and ensuring that they are properly formatted, you can improve the crawlability of your website and increase the chances of search engine bots properly indexing and crawling your content.
When it comes to server errors, one important factor to consider is the speed at which your website loads. Slow loading speeds can be caused by your web host, which can negatively impact your website’s crawlability and overall user experience. To address this issue, it’s crucial to ensure that your web host is not causing server errors and slowing down your website.
Another factor to consider is the channel width of your hosting plan. If your plan has limited bandwidth, it can affect the loading speed of your website. To optimize your website’s loading speed, it’s important to optimize your content, including code, images, videos, and other elements. Compressing images, minifying code, and optimizing video content can help reduce the loading time of your web pages.
To evaluate your website’s loading speed, you can use Google’s Pagespeed Insights tool. It provides valuable insights and recommendations on how to improve your website’s performance. If you find that your server errors are persisting despite optimizing your content, it may be worth considering migrating to a faster host with better channel width.
Addressing server errors requires optimizing your website’s loading speed by ensuring your web host is not causing slowdowns and optimizing your content. By doing so, you can improve your website’s crawlability and provide a better user experience.
Redirects are an essential aspect of website architecture that can greatly impact crawlability. When implementing redirects, it is crucial to do so properly to ensure search engine bots can efficiently crawl your website and index its content.
One common issue to avoid is looped redirects. These occur when a URL is redirected to another URL, which is then redirected back to the original URL, creating an endless loop. This can negatively affect crawlability as search engine bots get stuck in this loop and are unable to index the content effectively.
To address redirects, it is vital to use 301 redirects correctly. A 301 redirect is a permanent redirect that indicates to search engine bots that the original URL has permanently moved to a new location. This enables the bots to update their index accordingly and direct traffic to the new URL.
To identify redirect issues, tools like the HTTP Status Checker can be valuable. This tool allows you to examine the HTTP response codes of your URLs to determine if any redirects are not configured correctly. It provides insights into redirect chains and helps you identify and resolve any crawlability issues caused by redirects.
By implementing redirects properly and using tools to identify and address redirect issues, you can ensure optimal crawlability for your website, allowing search engine bots to navigate and index your content effectively.
Sitemaps play a crucial role in improving website crawlability for search engine crawlers. A sitemap is an XML file that lists all the pages on a website, making it easier for search engine bots to discover and index content. By creating and submitting a sitemap, website owners can ensure that search engines can efficiently crawl and understand their website’s structure.
To create a sitemap, follow these step-by-step instructions:
To submit your sitemap to Google:
By employing sitemaps, search engine crawlers can efficiently navigate your website, identify any server errors or broken links, and avoid indexing pages you do not want included in search results. Overall, submitting a sitemap is a vital part of optimizing your website’s crawlability for search engines.
To address the issue of blocking access on your website, it is crucial to check and properly configure your robots.txt file. This file tells search engine crawlers which pages they can and cannot access on your site. If there are mistakes or misconfigurations in this file, it can prevent crawlers from properly indexing your website.
The first step is to locate and review your robots.txt file. Ensure that it is properly formatted and includes the necessary directives. Double-check for any errors or sections that may be blocking access to important pages or sections of your site.
Blocking access to certain pages can have severe consequences for your website’s visibility in search engine results. Mass-deindexing can occur, leading to a significant loss of organic traffic. Search engine crawlers won’t be able to crawl and index your blocked pages, which means they won’t be included in search engine rankings.
Mistakenly blocking pages or sections of your site can result in a poor user experience as well. Visitors may encounter dead-end or error pages, leading to frustration and a negative impression of your site.
Regularly reviewing and updating your robots.txt file is essential for maintaining proper crawlability and preventing any unintended blocking of pages. By ensuring that search engine bots can access all relevant content on your site, you can help improve your website’s search engine optimization and online presence.
Crawl budget refers to the number of pages on a website that search engine crawlers are willing to crawl during a given time interval. It plays a crucial role in website optimization as it determines how efficiently search engines discover and index your content.
To maximize crawl budget, it is essential to prioritize important pages by ensuring they have high-quality and relevant content. This can be done by optimizing title tags, headings, and meta descriptions. Additionally, internal links should be used effectively to guide search engine crawlers towards these priority pages.
Removing duplicate pages is another important aspect of optimizing crawl budget. Duplicate content can confuse search engine crawlers and waste valuable resources. Utilizing canonical tags and implementing proper URL structure can help in resolving duplicate content issues.
Fixing broken links is vital as it improves user experience and ensures that search engine crawlers can navigate through your website without encountering errors. Broken links can hinder the crawling process and waste crawl budget.
Another factor to consider is the crawlability of CSS and Javascript files. These files should be easily accessible to search engine crawlers to ensure proper rendering and indexing.
Regularly checking crawl stats, updating sitemaps, and pruning unnecessary content are essential for effective crawl budget management. These practices help in identifying crawlability issues, optimizing crawl frequency for important pages, and ensuring that search engines have access to the latest and most relevant content.
In conclusion, understanding and optimizing crawl budget is crucial for website optimization. By prioritizing important pages, removing duplicate content, fixing broken links, and ensuring the crawlability of CSS and Javascript files, websites can maximize their crawl budget and improve their visibility in search engine results.
Making content crawlable for search engines is beneficial for a number of reasons. First, it allows search engines to index your content, making it easier for users to find it. Additionally, it increases the likelihood of your content being featured in search engine results pages (SERPs).
Making your content crawlable also helps to improve your website’s SEO ranking, since search engine algorithms take into account the number and quality of the links to your website. Finally, it allows you to take advantage of other SEO techniques, such as link building and keyword optimisation, to further increase your website’s ranking.
This helps to better reach your target audience, resulting in increased website traffic and potentially better profits. Having an optimised website also allows you to stay ahead of your competitors, as it helps ensure that your website is more easily discovered by potential customers, which in turn increases your market share of traffic and ultimately revenue.
A Robots.txt file is a text file placed in the root directory of a website that tells search engine crawlers which pages and files it should not crawl. This is helpful for websites that have pages or files that are not intended to be indexed, such as those that contain sensitive information or are behind a paywall.

It is important to note that Robots.txt is just a suggestion, and some search engine crawlers may not respect the instructions provided in the file. Furthermore, some malicious bots may ignore the instructions, so other measures should also be taken to protect sensitive information.
Structured data is a powerful tool for businesses seeking to optimise their online presence. By providing additional information about a webpage to search engines, you are able to better communicate the contents of the page, allowing for improved indexing and search engine ranking.
Structured data is commonly used to provide information about products, services, events, and other objects, increasing the visibility of your offerings. This data is created using schema.org, an open, shared markup language for annotation.
Utilising structured data as part of your optimisation strategy can be a great way to increase the visibility of your business and boost your ranking in search engine results.
Having a well-organized site structure and an effective internal linking system is crucial for optimizing crawlability. These elements help web crawlers discover and navigate through your website efficiently, ensuring that all your valuable content gets indexed and ranked by search engines.
A solid site structure allows search engine bots to easily understand the hierarchy and relationships between different pages on your website. This helps them determine the relevance and importance of each page, leading to better crawlability and indexability.
Internal links play a key role in connecting your website’s pages to one another. Not only do they assist visitors in navigating through your site, but they also guide search engine crawlers to discover and access different pages. By incorporating relevant and contextual internal links throughout your website, you provide clear paths for crawlers to follow and ensure that all your content is effectively crawled and indexed.
To optimise crawlability, it’s important to avoid orphaned pages. These are pages on your website that are not linked to from any other pages. Orphaned pages are difficult for search engine crawlers to find and access, leading to poor crawlability. Therefore, it’s essential to ensure that all your pages have appropriate internal links pointing to them, making it easier for search engine bots to discover, crawl, and index your content.
By paying attention to your site structure, internal link system, and avoiding orphaned pages, you can greatly improve the crawlability of your website, and as a result, enhance its visibility and organic traffic.
Using a canonical tag is an effective way of ensuring that search engines index and crawl the right content. This is done by adding a tag to the HTML of the page containing the content that should be considered the canonical page. This tag will inform search engines that the page is the main page for that content, and should be the page indexed and crawled.
This is particularly useful for websites that have duplicate content, as it allows search engines to know which page should be given priority. It is important to note that canonical tags should only be used when absolutely necessary, as it can have unintended consequences if used too frequently.

To use a canonical tag, simply add a “link rel” tag to the HTML of the page containing the content that you want to be the canonical page. This will tell search engines that the page is the main page for that content and should be indexed and crawled.
Site structure and navigation is an important element of website crawlability. It is important to create a structure and navigation that helps search engine crawlers understand the hierarchy of your website and determine which pages are important.
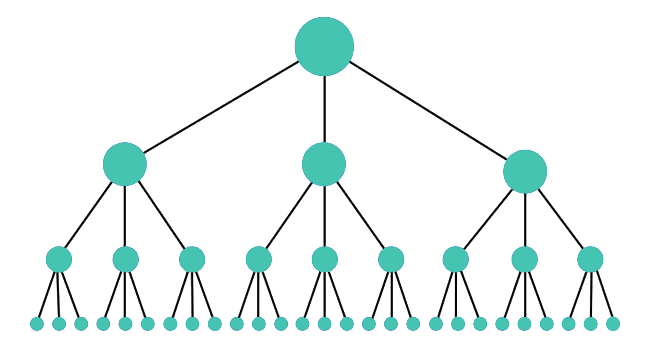
A well-structured website will have a logical navigation that uses HTML links to link pages together and make it easier for search engine crawlers to access the content. Additionally, it’s important to have a sitemap that makes it easier for search engines to understand your website structure. Having a properly structured site architecture and navigation will ensure that search engine crawlers can access and crawl your content with ease.
Optimising your content for maximum website crawlability is essential to ensure that search engines can properly index and rank your webpages. This can be done by organising your content in a structured and logical manner and making it easier for search engine crawlers to access and understand the content. You can also make sure your website is mobile-friendly and that it loads quickly, as slow loading times can cause crawlers to miss important content on your site. Additionally, it is important to add unique and relevant titles and meta descriptions to your pages as well as having clear page hierarchy and using internal links to make it easier for crawlers to access all of your website’s content.
Website crawlability is an important factor to consider when creating a website. It is a good practice to ensure that your content is crawlable so that search engines can easily index your content and make it easier for users to access. Implementing proper SEO techniques, using proper tags and meta descriptions, and setting up the sitemap are all essential elements to ensuring crawlability. With proper crawlability, your website will be more discoverable and rank higher in search engine results.
Looking for help with any of the topics outlined above? Contact us today and let us know.

 0800 1455349
0800 1455349


